dbPEX – PEX-genendatabase
Missie
Door genetische variaties te catalogiseren die betrokken zijn bij peroxisomale assemblageziekten, hopen we de analyse van deze variaties te versnellen en hun rol in gezondheid en ziekte beter te begrijpen.
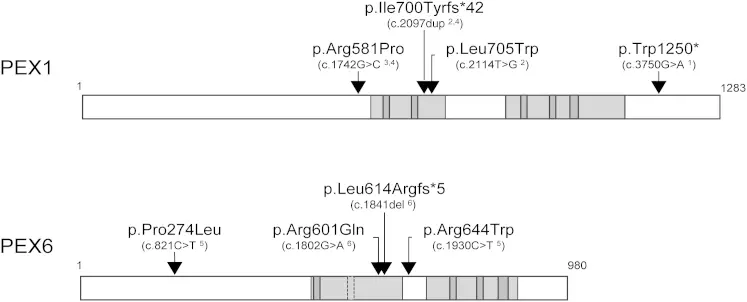
PEX1: (peroxisomale biogenesefactor 1)
Algemene informatie over PEX1
Veld |
Inhoud |
|---|---|
| Gensymbool | PEX1 |
| Gennaam | peroxisomale biogenesefactor 1 |
| Chromosoom | 7 |
| Chromosomale band | q21.2 |
| Genetische imprinting | Onbekend |
| Genomische referentie | NG_008341.2 |
| Transcriptreferentie | NM_000466.2 |
| Geassocieerd met ziekten | HMLR1, ID, PBD1A, PBD1B |
| Totaal aantal publieke varianten | 932 |
| Unieke publieke DNA-varianten | 257 |
| Individuen met publieke varianten | 602 |
| Verborgen varianten | 31 |
PEX2: (peroxisomale biogenesefactor 2)
Algemene informatie over PEX2
| Veld | Inhoud |
|---|---|
| Gensymbool | PEX2 |
| Gennaam | peroxisomale biogenesefactor 2 |
| Chromosoom | 8 |
| Chromosomale band | q21.11 |
| Genetische imprinting | Onbekend |
| Genomische referentie | NG_008371.1 |
| Transcriptreferentie | NM_000318.2 |
| Geassocieerd met ziekten | PBD5A, PBD5B |
| Totaal aantal publieke varianten | 67 |
| Unieke publieke DNA-varianten | 46 |
| Individuen met publieke varianten | 38 |
| Verborgen varianten | 4 |

PEX3: (peroxisomale biogenesefactor 3)
Algemene informatie over PEX3
| Veld | Inhoud |
|---|---|
| Gensymbool | PEX3 |
| Gennaam | peroxisomale biogenesefactor 3 |
| Chromosoom | 6 |
| Chromosomale band | q24.2 |
| Genetische imprinting | Onbekend |
| Genomische referentie | NG_008459.1 |
| Transcriptreferentie | NM_003630.2 |
| Geassocieerd met ziekten | PBD10A, PBD10B |
| Totaal aantal publieke varianten | 21 |
| Unieke publieke DNA-varianten | 21 |
| Individuen met publieke varianten | 8 |
| Verborgen varianten | – |
PEX5: (peroxisomale biogenesefactor 5)
Algemene informatie over PEX5
| Veld | Inhoud |
|---|---|
| Gensymbool | PEX5 |
| Gennaam | peroxisomale biogenesefactor 5 |
| Chromosoom | 12 |
| Chromosomale band | p |
| Genetische imprinting | Onbekend |
| Genomische referentie | NG_008448.1 |
| Transcriptreferentie | NM_000319.4 |
| Geassocieerd met ziekten | ID, PBD2A, PBD2B, RCDP5 |
| Totaal aantal publieke varianten | 65 |
| Unieke publieke DNA-varianten | 52 |
| Individuen met publieke varianten | 178 |
| Verborgen varianten | 7 |
PEX6: (peroxisomale biogenesefactor 6)
Algemene informatie over PEX6
| Veld | Inhoud |
|---|---|
| Gensymbool | PEX6 |
| Gennaam | peroxisomale biogenesefactor 6 |
| Chromosoom | 6 |
| Chromosomale band | p22–p11 |
| Genetische imprinting | Onbekend |
| Genomische referentie | NG_008370.1 |
| Transcriptreferentie | NM_000287.3 |
| Geassocieerd met ziekten | HMLR2, PBD4A, PBD4B |
| Totaal aantal publieke varianten | 329 |
| Unieke publieke DNA-varianten | 211 |
| Individuen met publieke varianten | 340 |
| Verborgen varianten | 9 |
PEX7: (peroxisomale biogenesefactor 7)
Algemene informatie over PEX7
| Veld | Inhoud |
|---|---|
| Gensymbool | PEX7 |
| Gennaam | peroxisomale biogenesefactor 7 |
| Chromosoom | 6 |
| Chromosomale band | q21–q22.2 |
| Genetische imprinting | Onbekend |
| Genomische referentie | NG_008462.1 |
| Transcriptreferentie | NM_000288.3 |
| Geassocieerd met ziekten | ID, PBD9B, RCDP1, Refsum |
| Totaal aantal publieke varianten | 294 |
| Unieke publieke DNA-varianten | 98 |
| Individuen met publieke varianten | 172 |
| Verborgen varianten | 11 |
PEX13: (peroxisomale biogenesefactor 13)
Algemene informatie over PEX13
| Veld | Inhoud |
|---|---|
| Gensymbool | PEX13 |
| Gennaam | peroxisomale biogenesefactor 13 |
| Chromosoom | 2 |
| Chromosomale band | p16.1 |
| Genetische imprinting | Onbekend |
| Genomische referentie | NG_008665.1 |
| Transcriptreferentie | NM_002618.3 |
| Geassocieerd met ziekten | ID, PBD11A, PBD11B |
| Totaal aantal publieke varianten | 25 |
| Unieke publieke DNA-varianten | 23 |
| Individuen met publieke varianten | 11 |
| Verborgen varianten | 2 |
PEX19: (peroxisomale biogenesefactor 19)
Algemene informatie over PEX19
| Veld | Inhoud |
|---|---|
| Gensymbool | PEX19 |
| Gennaam | peroxisomale biogenesefactor 19 |
| Chromosoom | 1 |
| Chromosomale band | q22 |
| Genetische imprinting | Onbekend |
| Genomische referentie | NG_008637.1 |
| Transcriptreferentie | NM_002857.3 |
| Geassocieerd met ziekten | PBD12A |
| Totaal aantal publieke varianten | 45 |
| Unieke publieke DNA-varianten | 38 |
| Individuen met publieke varianten | 7 |
| Verborgen varianten | 6 |
PEX26: (peroxisomale biogenesefactor 26)
Algemene informatie over PEX26
| Veld | Inhoud |
|---|---|
| Gensymbool | PEX26 |
| Gennaam | peroxisomale biogenesefactor 26 |
| Chromosoom | 22 |
| Chromosomale band | q11.21 |
| Genetische imprinting | Onbekend |
| Genomische referentie | NG_008339.1 |
| Transcriptreferentie | NM_017929.5 |
| Geassocieerd met ziekten | ID, PBD7A, PBD7B |
| Totaal aantal publieke varianten | 83 |
| Unieke publieke DNA-varianten | 47 |
| Individuen met publieke varianten | 60 |
| Verborgen varianten | 6 |

dbPEX-beleid
Disclaimer
dbPEX is niet bedoeld voor klinisch gebruik, waaronder diagnose, genetische counseling of behandeling van een gezondheidsprobleem of ziekte. dbPEX verstrekt ook geen medisch advies en raadt gebruikers aan om gekwalificeerde professionals te raadplegen voor diagnose, genetische counseling of behandeling van gezondheidsproblemen of ziekten, of voor antwoorden op persoonlijke vragen.
Aansprakelijkheid
dbPEX betracht alle redelijke zorg om ervoor te zorgen dat de database en de daarin opgenomen gegevens van hoge kwaliteit zijn; het geeft echter geen garantie, expliciet of impliciet, met betrekking tot de juistheid of volledigheid daarvan, noch dat deze database of de daarin opgenomen gegevens geschikt zijn voor een bepaald doel, zoals diagnose, genetische counseling of behandeling van patiënten. dbPEX aanvaardt geen aansprakelijkheid voor gevolgen die voortvloeien uit eventuele onjuistheden, weglatingen of verkeerd gebruik van de informatie.
Laten we contact maken
Kom in contact met je klanten om ze betere service te bieden. Je kunt de formuliervelden aanpassen om preciezere informatie te verzamelen.